

Note: This post discusses cutting edge cryptographic techniques. It is intended to give a view into research at Julia Computing. Do not use any examples in this blog post for production applications. Always consult a professional cryptographer before using cryptography.
TL;DR: click here to go directly to the package that implements the magic and here for the code that we'll be talking about in this blog post.
Introduction
Suppose you have just developed a spiffy new machine learning model (using Flux.jl of course) and now want to start deploying it for your users. How do you go about doing that? Probably the simplest thing would be to just ship your model to your users and let them run it locally on their data. However there are a number of problems with this approach:
-
ML models are large and the user's device may not have enough storage or computation to actually run the model.
-
ML models are often updated frequently and you may not want to send the large model across the network that often.
-
Developing ML models takes a lot of time and computational resources, which you may want to recover by charging your users for making use of your model.
The solution that usually comes next is expose the model as an API on the cloud. These machine learning-as-a-service offerings have sprung up in mass over the past few years, with every major cloud platform offering such services to the enterprising developer. The dilemma for potential users of such products is obvious: User data is now processed on some remote server that may not necessarily be trustworthy. This has clear ethical and legal ramifications that limit the areas where such solutions can be effective. In regulated industries, such as medicine or finance in particular, sending patient or financial data to third parties for processing is often a no-go. Can we do better?
As it turns out we can! Recent breakthroughs in cryptography have made it practical to perform computation on data without ever decrypting it. In our example, the user would send encrypted data (e.g. images) to the cloud API, which would run the machine learning model and then return the encrypted answer. Nowhere was the user data decrypted and in particular the cloud provider does not have access to either the orignal image nor is it able to decrypt the prediction it computed. How is this possible? Let's find out by building a machine learning service for handwriting recognition of encrypted images (from the MNIST dataset).
HE generally
The ability to compute on encrypted data is generally referred to as "secure computation" and is a fairly large area of research, with many different cryptographic approaches and techniques for a plethora of different application scenarios. For our example, we will be focusing on a technique known as "homomorphic encryption". In a homomorphic encryption system, we generally have the following operations available:
-
pub_key, eval_key, priv_key = keygen() -
encrypted = encrypt(pub_key, plaintext) -
decrypted = decrypt(priv_key, encrypted) -
encrypted′ = eval(eval_key, f, encrypted)
the first three are fairly straightforward and should be familiar to anyone who has used any sort of asymmetric cryptography before (as you did when you connected to this blog post via TLS). The last operation is where the magic is. It evaluates some function f on the encryption and returns another encrypted value corresponding to the result of evaluting f on the encrypted value. It is this property that gives homomorphic computation its name. Evaluation commutes with the encryption operation:
f(decrypt(priv_key, encrypted)) == decrypt(priv_key, eval(eval_key, f, encrypted))(Equivalently it is possible to evaluate arbitrary homomorphisms f on the encrypted value).
Which functions f are supported depends on the cryptographic schemes and depending on the supported operations. If only one f is supported (e.g. f = +), we call an encryption scheme "partially homomorphic". If f can be any complete set of gates out of which we can build arbitrary circuits, we call the computation "somewhat homomorphic" if the size of the circuit is limited or "fully homomorphic" if the size of the circuit is unlimited. It is often possible to turn "somehwhat" into "fully" homomorphic encryption through a technique known as bootstrapping though that is beyond the scope of the current blog post. Fully homomorphic encryption is a fairly recent discovery, with the first viable (though not practical) scheme published by Craig Gentry in 2009. There are several more recent (and practical) FHE schemes. More importantly, there are software packages that implement them efficiently. The two most commonly used ones are probably Microsoft SEAL and PALISADE. In addition, I recently open sourced a pure julia implementation of these algorithms. For our purposes we will be using the CKKS encryption as implemented in the latter.
CKKS High Level
CKKS (named after Cheon-Kim-Kim-Song, the authors of the 2016 paper that proposed it) is a homomorphic encryption scheme that allows homomorphic evaluation of the following primitive operations:
-
Elementwise addition of length
nvectors of complex numbers -
Elementwise multiplication of length
ncomplex vectors -
Rotation (in the
circshiftsense) of elements in the vector -
Complex conjugation of vector elements
The parameter n here depends on the desired security and precision and is generally relatively high. For our example it will be 4096 (higher numbers are more secure, but also more expensive, scaling as roughly n log n).
Additionally, computations using CKKS are noisy. As a result, computational results are only approximate and care must be taken to ensure that results are evaluated with sufficient precision to not affect the correctness of a result.
That said, these restrictions are not all that unusual to developers of machine learning packages. Special purpose accelerators like GPUs also generally operate on vectors of numbers. Likewise, for many developers floating point numbers can sometimes feel noisy due to effects of algorithms selection, multithreading etc. (I want to emphasize that there is a crucial difference here in that floating point arithmetic is inherently deterministic, even if it sometimes doesn't appear that way due to complexity of the implementation, while the CKKS primitives really are noisy, but perhaps this allows users to appreciate that noisyness is not as scary as it might at first appear).
With that in mind, let's see how we can perform these operations in Julia (note: these are highly insecure parameter choices, the purpose of these operations is to illustrate usage of the library at the REPL)
julia> using ToyFHE
# Let's play with 8 element vectors
julia> N = 8;
# Choose some parameters - we'll talk about it later
julia> ℛ = NegacyclicRing(2N, (40, 40, 40))
ℤ₁₃₂₉₂₂₇₉₉₇₅₆₈₀₈₁₄₅₇₄₀₂₇₀₁₂₀₇₁₀₄₂₄₈₂₅₇/(x¹⁶ + 1)
# We'll use CKKS
julia> params = CKKSParams(ℛ)
CKKS parameters
# We need to pick a scaling factor for a numbers - again we'll talk about that later
julia> Tscale = FixedRational{2^40}
FixedRational{1099511627776,T} where T
# Let's start with a plain Vector of zeros
julia> plain = CKKSEncoding{Tscale}(zero(ℛ))
8-element CKKSEncoding{FixedRational{1099511627776,T} where T} with indices 0:7:
0.0 + 0.0im
0.0 + 0.0im
0.0 + 0.0im
0.0 + 0.0im
0.0 + 0.0im
0.0 + 0.0im
0.0 + 0.0im
0.0 + 0.0im
# Ok, we're ready to get started, but first we'll need some keys
julia> kp = keygen(params)
CKKS key pair
julia> kp.priv
CKKS private key
julia> kp.pub
CKKS public key
# Alright, let's encrypt some things:
julia> foreach(i->plain[i] = i+1, 0:7); plain
8-element CKKSEncoding{FixedRational{1099511627776,T} where T} with indices 0:7:
1.0 + 0.0im
2.0 + 0.0im
3.0 + 0.0im
4.0 + 0.0im
5.0 + 0.0im
6.0 + 0.0im
7.0 + 0.0im
8.0 + 0.0im
julia> c = encrypt(kp.pub, plain)
CKKS ciphertext (length 2, encoding CKKSEncoding{FixedRational{1099511627776,T} where T})
# And decrypt it again
julia> decrypt(kp.priv, c)
8-element CKKSEncoding{FixedRational{1099511627776,T} where T} with indices 0:7:
0.9999999999995506 - 2.7335193113350057e-16im
1.9999999999989408 - 3.885780586188048e-16im
3.000000000000205 + 1.6772825551165524e-16im
4.000000000000538 - 3.885780586188048e-16im
4.999999999998865 + 8.382500573679615e-17im
6.000000000000185 + 4.996003610813204e-16im
7.000000000001043 - 2.0024593503998215e-16im
8.000000000000673 + 4.996003610813204e-16im
# Note that we had some noise. Let's go through all the primitive operations we'll need:
julia> decrypt(kp.priv, c+c)
8-element CKKSEncoding{FixedRational{1099511627776,T} where T} with indices 0:7:
1.9999999999991012 - 5.467038622670011e-16im
3.9999999999978817 - 7.771561172376096e-16im
6.00000000000041 + 3.354565110233105e-16im
8.000000000001076 - 7.771561172376096e-16im
9.99999999999773 + 1.676500114735923e-16im
12.00000000000037 + 9.992007221626409e-16im
14.000000000002085 - 4.004918700799643e-16im
16.000000000001346 + 9.992007221626409e-16im
julia> csq = c*c
CKKS ciphertext (length 3, encoding CKKSEncoding{FixedRational{1208925819614629174706176,T} where T})
julia> decrypt(kp.priv, csq)
8-element CKKSEncoding{FixedRational{1208925819614629174706176,T} where T} with indices 0:7:
0.9999999999991012 - 2.350516767363621e-15im
3.9999999999957616 - 5.773159728050814e-15im
9.000000000001226 - 2.534464540987068e-15im
16.000000000004306 - 2.220446049250313e-15im
24.99999999998865 + 2.0903753311370056e-15im
36.00000000000222 + 4.884981308350689e-15im
49.000000000014595 + 1.0182491378134327e-15im
64.00000000001077 + 4.884981308350689e-15imThat was easy! The eagle eyed reader may have noticed that csq looks a bit different from the previous ciphertext. In particular, it is a "length 3" ciphertext and the scale is much larger. What these are and what they do is a bit too complicated for this point in the blog post, but suffice it to say, we want to get these back down before we do further computation, or we'll run out of "space" in the ciphertext. Luckily, there is a way to do these for each of the two aspects that grew:
# To get back down to length 2, we need to `keyswitch` (aka
# relinerarize), which requires an evaluation key. Generating
# this requires the private key. In a real application we would
# have generated this up front and sent it along with the encrypted
# data, but since we have the private key, we can just do it now.
julia> ek = keygen(EvalMultKey, kp.priv)
CKKS multiplication key
julia> csq_length2 = keyswitch(ek, csq)
CKKS ciphertext (length 2, encoding CKKSEncoding{FixedRational{1208925819614629174706176,T} where T})
# Getting the scale back down is done using modswitching.
julia> csq_smaller = modswitch(csq_length2)
CKKS ciphertext (length 2, encoding CKKSEncoding{FixedRational{1.099511626783e12,T} where T})
# And it still decrypts correctly (though note we've lost some precision)
julia> decrypt(kp.priv, csq_smaller)
8-element CKKSEncoding{FixedRational{1.099511626783e12,T} where T} with indices 0:7:
0.9999999999802469 - 5.005163520332181e-11im
3.9999999999957723 - 1.0468514951188039e-11im
8.999999999998249 - 4.7588542623100616e-12im
16.000000000023014 - 1.0413447889166631e-11im
24.999999999955193 - 6.187833723406491e-12im
36.000000000002345 + 1.860733715346631e-13im
49.00000000001647 - 1.442396043149794e-12im
63.999999999988695 - 1.0722489563648028e-10imAdditionally, modswitching (short for modulus switching) reduces the size of the ciphertext modulus, so we can't just keep doing this indefinitely. (In the terminology from above, we're using a SHE scheme):
julia> ℛ # Remember the ring we initially created
ℤ₁₃₂₉₂₂₇₉₉₇₅₆₈₀₈₁₄₅₇₄₀₂₇₀₁₂₀₇₁₀₄₂₄₈₂₅₇/(x¹⁶ + 1)
julia> ToyFHE.ring(csq_smaller) # It shrunk!
ℤ₁₂₀₈₉₂₅₈₂₀₁₄₄₅₉₃₇₇₉₃₃₁₅₅₃/(x¹⁶ + 1)There's one last operation we'll need: rotations. Like keyswitching above, this requires an evaluation key (also called a galois key):
julia> gk = keygen(GaloisKey, kp.priv; steps=2)
CKKS galois key (element 25)
julia> decrypt(kp, circshift(c, gk))
8-element CKKSEncoding{FixedRational{1099511627776,T} where T} with indices 0:7:
7.000000000001042 + 5.68459112632516e-16im
8.000000000000673 + 5.551115123125783e-17im
0.999999999999551 - 2.308655353580721e-16im
1.9999999999989408 + 2.7755575615628914e-16im
3.000000000000205 - 6.009767921608429e-16im
4.000000000000538 + 5.551115123125783e-17im
4.999999999998865 + 4.133860996136768e-17im
6.000000000000185 - 1.6653345369377348e-16im
# And let's compare to doing the same on the plaintext
julia> circshift(plain, 2)
8-element OffsetArray(::Array{Complex{Float64},1}, 0:7) with eltype Complex{Float64} with indices 0:7:
7.0 + 0.0im
8.0 + 0.0im
1.0 + 0.0im
2.0 + 0.0im
3.0 + 0.0im
4.0 + 0.0im
5.0 + 0.0im
6.0 + 0.0imAlright, we've covered the basic usage of the HE library. Before we get started thinking about how to perform neural network inference using these primitives, let's look at and train the neural network we'll be using.
The machine learning model
If you're not familiar with machine learning, or the Flux.jl machine learning library, I'd recommend a quick detour to the Flux.jl documentation or our free Introduction to Machine Learning course on JuliaAcademy, since we'll only be discussing the changes for running the model on encrypted data.
Our starting point is the convolutional neural network example in the Flux model zoo. We'll keep the training loop, data preparation, etc. the same and just tweak the model slightly. The model we'll use is:
function reshape_and_vcat(x)
let y=reshape(x, 64, 4, size(x, 4))
vcat((y[:,i,:] for i=axes(y,2))...)
end
end
model = Chain(
# First convolution, operating upon a 28x28 image
Conv((7, 7), 1=>4, stride=(3,3), x->x.^2),
reshape_and_vcat,
Dense(256, 64, x->x.^2),
Dense(64, 10),
)This is essentially the same model as the one used in the paper "Secure Outsourced Matrix Computation and Application to Neural Networks", which uses the same cryptographic scheme for the same demo, with two differences: 1) They also encrypt the model, which we neglect here for simplicity and 2) We have bias vectors after every layer (which is what Flux will do by default), which I'm not sure was the case for the model evaluated in the paper. Perhaps because of 2), the test set accuracy of our model is slightly higher (98.6% vs 98.1%), but this may of course also just come down to hyperparameter differences.
An unusual feature (for those coming from a machine learning background) are the x.^2 activation functions. More common choices here would be something like tanh or relu or something fancier than that. However, while those functions (relu in particular) are cheap to evaluate on plaintext values, they would be quite expensive to evaluated encryptedly (we'd basically evaluate a polynomial approximation). Luckily x.^2 works fine our our purposes.
The rest of the training loop is basically the same. The softmax was removed from the model in favor of a logitcrossentropy loss function (though of course we could have kept it and just evaluated the softmax after decryption on the client). The full code to train this model is on GitHub and completes in a few minutes on any recent GPU.
Performing the operations efficiently
Alright, now that we know what we need to do, let's take stock of what operations we need to be able to do:
-
Convolutions
-
Elementwise Squaring
-
Matrix Multiply
Squaring is trivial, we already saw that above, so let's tackle the other two in order. Throughout we'll be assuming that we're working with a batch size of 64 (you may note that the model parameters and batch size were strategically chosen to take good advantage of a 4096 element vector which is what we get from realistic parameter choices).
Convolution
Let us recall how convolution works. We take some window (in our case 7x7) of the original input array and for each element in the window multiply by an element of the convolution mask. Then we move the window over some (in our case, the stride is 3, so we move over by 3 elements) and repeat the process (with the same convolution mask). This process is illustrated in the following animation (source) for a 3x3 convolution with stride (2, 2) (the blue array is the input, the green array the output):
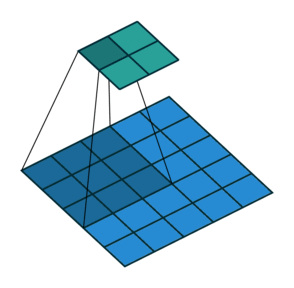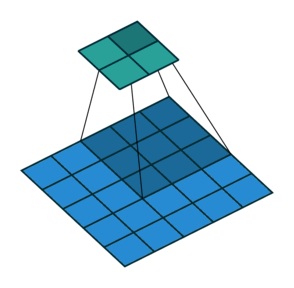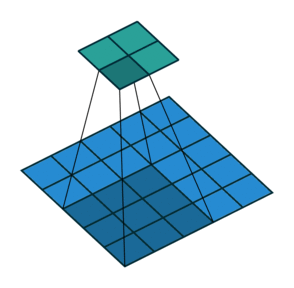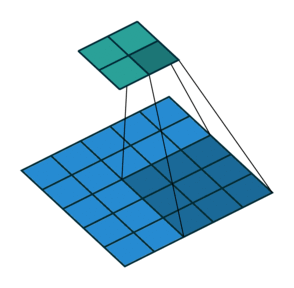
Additionally, we have convolutions into 4 different "channels" (all this means is that we repeat the convolution 3 more times with different convolution masks).
Alright, so now that we know what we're doing let's figure out how to do it. We're in luck in that the convolution is the first thing in our model. As a result, we can do some preprocessing on the client before encrypting the data (without needing the model weights) to save us some work. In particular, we'll do the following:
-
Precompute each convolution window (i.e. 7x7 extraction from the original images), giving us 64 7x7 matrices per input image (note for 7x7 windows with stride 2 there are 8x8 convolution windows to evaluate per 28x28 input image)
-
Collect the same position in each window into one vector, i.e. we'll have a 64-element vector for each image or a 64x64 element vector for a batch of 64 (i.e. a total of 49 64x64 matrices)
-
Encrypt that
The convolution then simply becomes scalar multiplication of the whole matrix with the appropriate mask element, and by summing all 49 elements later, we the result of the convolution. An implementation of this strategy (on the plaintext) may look like:
function public_preprocess(batch)
ka = OffsetArray(0:7, 0:7)
# Create feature extracted matrix
I = [[batch[i′*3 .+ (1:7), j′*3 .+ (1:7), 1, k] for i′=ka, j′=ka] for k = 1:64]
# Reshape into the ciphertext
Iᵢⱼ = [[I[k][l...][i,j] for k=1:64, l=product(ka, ka)] for i=1:7, j=1:7]
end
Iᵢⱼ = public_preprocess(batch)
# Evaluate the convolution
weights = model.layers[1].weight
conv_weights = reverse(reverse(weights, dims=1), dims=2)
conved = [sum(Iᵢⱼ[i,j]*conv_weights[i,j,1,channel] for i=1:7, j=1:7) for channel = 1:4]
conved = map(((x,b),)->x .+ b, zip(conved, model.layers[1].bias))which (modulo a reordering of the dimension) gives the same answer as, but using operations
model.layers[1](batch)Adding the encryption operations, we have:
Iᵢⱼ = public_preprocess(batch)
C_Iᵢⱼ = map(Iᵢⱼ) do Iij
plain = CKKSEncoding{Tscale}(zero(plaintext_space(ckks_params)))
plain .= OffsetArray(vec(Iij), 0:(N÷2-1))
encrypt(kp, plain)
end
weights = model.layers[1].weight
conv_weights = reverse(reverse(weights, dims=1), dims=2)
conved3 = [sum(C_Iᵢⱼ[i,j]*conv_weights[i,j,1,channel] for i=1:7, j=1:7) for channel = 1:4]
conved2 = map(((x,b),)->x .+ b, zip(conved3, model.layers[1].bias))
conved1 = map(ToyFHE.modswitch, conved2)Note that a keyswitch isn't required because the weights are public, so we didn't expand the length of the ciphertext.
Matrix multiply
Moving on to matrix multiply, we take advantage of the fact that we can rotate elements in the vector to effect a re-ordering of the multiplication indices. In particular, consider a row-major ordering of matrix elements in the vector. Then, if we shift the vector by a multiple of the row-size, we get the effect of rotating the columns, which is a sufficient primitive for implementing matrix multiply (of square matrices at least). Let's try it:
function matmul_square_reordered(weights, x)
sum(1:size(weights, 1)) do k
# We rotate the columns of the LHS and take the diagonal
weight_diag = diag(circshift(weights, (0,(k-1))))
# We rotate the rows of the RHS
x_rotated = circshift(x, (k-1,0))
# We do an elementwise, broadcast multiply
weight_diag .* x_rotated
end
end
function matmul_reorderd(weights, x)
sum(partition(1:256, 64)) do range
matmul_square_reordered(weights[:, range], x[range, :])
end
end
fc1_weights = model.layers[3].W
x = rand(Float64, 256, 64)
@assert (fc1_weights*x) ≈ matmul_reorderd(fc1_weights, x)Of course for general matrix multiply, we may want something fancier, but it'll do for now.
Making it nicer
At this point, we've managed to get everything together and indeed it works. For reference, here it is in all its glory (omitting setup for parameter selection and the like):
ek = keygen(EvalMultKey, kp.priv)
gk = keygen(GaloisKey, kp.priv; steps=64)
Iᵢⱼ = public_preprocess(batch)
C_Iᵢⱼ = map(Iᵢⱼ) do Iij
plain = CKKSEncoding{Tscale}(zero(plaintext_space(ckks_params)))
plain .= OffsetArray(vec(Iij), 0:(N÷2-1))
encrypt(kp, plain)
end
weights = model.layers[1].weight
conv_weights = reverse(reverse(weights, dims=1), dims=2)
conved3 = [sum(C_Iᵢⱼ[i,j]*conv_weights[i,j,1,channel] for i=1:7, j=1:7) for channel = 1:4]
conved2 = map(((x,b),)->x .+ b, zip(conved3, model.layers[1].bias))
conved1 = map(ToyFHE.modswitch, conved2)
Csqed1 = map(x->x*x, conved1)
Csqed1 = map(x->keyswitch(ek, x), Csqed1)
Csqed1 = map(ToyFHE.modswitch, Csqed1)
function encrypted_matmul(gk, weights, x::ToyFHE.CipherText)
result = repeat(diag(weights), inner=64).*x
rotated = x
for k = 2:64
rotated = ToyFHE.rotate(gk, rotated)
result += repeat(diag(circshift(weights, (0,(k-1)))), inner=64) .* rotated
end
result
end
fq1_weights = model.layers[3].W
Cfq1 = sum(enumerate(partition(1:256, 64))) do (i,range)
encrypted_matmul(gk, fq1_weights[:, range], Csqed1[i])
end
Cfq1 = Cfq1 .+ OffsetArray(repeat(model.layers[3].b, inner=64), 0:4095)
Cfq1 = modswitch(Cfq1)
Csqed2 = Cfq1*Cfq1
Csqed2 = keyswitch(ek, Csqed2)
Csqed2 = modswitch(Csqed2)
function naive_rectangular_matmul(gk, weights, x)
@assert size(weights, 1) < size(weights, 2)
weights = vcat(weights, zeros(eltype(weights), size(weights, 2)-size(weights, 1), size(weights, 2)))
encrypted_matmul(gk, weights, x)
end
fq2_weights = model.layers[4].W
Cresult = naive_rectangular_matmul(gk, fq2_weights, Csqed2)
Cresult = Cresult .+ OffsetArray(repeat(vcat(model.layers[4].b, zeros(54)), inner=64), 0:4095)Not very pretty to look at, but hopefully if you have made it this far in the blog post, you should be able to understand each step in the sequence.
Now, let's turn our attention to thinking about some abstractions that would make all this easier. We're now leaving the realm of cryptography and machine learning and arriving at programming language design, so let's take advantage of fact that Julia allows powerful abstractions and go through the exercise of building some. For example, we could encapsulate the whole convolution extraction process as a custom array type:
using BlockArrays
"""
ExplodedConvArray{T, Dims, Storage} <: AbstractArray{T, 4}
Represents a an `nxmx1xb` array of images, but rearranged into a
series of convolution windows. Evaluating a convolution compatible
with `Dims` on this array is achievable through a sequence of
scalar multiplications and sums on the underling storage.
"""
struct ExplodedConvArray{T, Dims, Storage} <: AbstractArray{T, 4}
# sx*sy matrix of b*(dx*dy) matrices of extracted elements
# where (sx, sy) = kernel_size(Dims)
# (dx, dy) = output_size(DenseConvDims(...))
cdims::Dims
x::Matrix{Storage}
function ExplodedConvArray{T, Dims, Storage}(cdims::Dims, storage::Matrix{Storage}) where {T, Dims, Storage}
@assert all(==(size(storage[1])), size.(storage))
new{T, Dims, Storage}(cdims, storage)
end
end
Base.size(ex::ExplodedConvArray) = (NNlib.input_size(ex.cdims)..., 1, size(ex.x[1], 1))
function ExplodedConvArray{T}(cdims, batch::AbstractArray{T, 4}) where {T}
x, y = NNlib.output_size(cdims)
kx, ky = NNlib.kernel_size(cdims)
stridex, stridey = NNlib.stride(cdims)
kax = OffsetArray(0:x-1, 0:x-1)
kay = OffsetArray(0:x-1, 0:x-1)
I = [[batch[i′*stridex .+ (1:kx), j′*stridey .+ (1:ky), 1, k] for i′=kax, j′=kay] for k = 1:size(batch, 4)]
Iᵢⱼ = [[I[k][l...][i,j] for k=1:size(batch, 4), l=product(kax, kay)] for (i,j) in product(1:kx, 1:ky)]
ExplodedConvArray{T, typeof(cdims), eltype(Iᵢⱼ)}(cdims, Iᵢⱼ)
end
function NNlib.conv(x::ExplodedConvArray{<:Any, Dims}, weights::AbstractArray{<:Any, 4}, cdims::Dims) where {Dims<:ConvDims}
blocks = reshape([ Base.ReshapedArray(sum(x.x[i,j]*weights[i,j,1,channel] for i=1:7, j=1:7), (NNlib.output_size(cdims)...,1,size(x, 4)), ()) for channel = 1:4 ],(1,1,4,1))
BlockArrays._BlockArray(blocks, BlockArrays.BlockSizes([8], [8], [1,1,1,1], [64]))
endNote that here we made use BlockArrays back to represent a 8x8x4x64 array as 4 8x8x1x64 arrays as in the original code. Ok, so now we already have a much nicer representation of the first step, at least on unencrypted arrays:
julia> cdims = DenseConvDims(batch, model.layers[1].weight; stride=(3,3), padding=(0,0,0,0), dilation=(1,1))
DenseConvDims: (28, 28, 1) * (7, 7) -> (8, 8, 4), stride: (3, 3) pad: (0, 0, 0, 0), dil: (1, 1), flip: false
julia> a = ExplodedConvArray{eltype(batch)}(cdims, batch);
julia> model(a)
10×64 Array{Float32,2}:
[snip]How do we bring this into the encrypted world? Well, we need to do two things:
-
We want to encrypt a struct (
ExplodedConvArray) in such a way that each that we get a ciphertext for each field. Then, operations on this encrypted struct work by looking up what the function would have done on the original struct and simply doing the same homomorphically. -
We want to intercept certain operations to be done differently in the encrypted context.
Luckily, Julia, provides an abstraction that lets us a do both: A compiler plugin-in using the Cassette.jl mechanism. How this works and how to use it is a bit of a complicated story, so I will omit it from this blog, post, but briefly, you can define a Context (say Encrypted and then define rules for how operations under this context work). For example, for the second requirement might be written, as:
# Define Matrix multiplication between an array and an encrypted block array
function (*::Encrypted{typeof(*)})(a::Array{T, 2}, b::Encrypted{<:BlockArray{T, 2}}) where {T}
sum(a*b for (i,range) in enumerate(partition(1:size(a, 2), size(b.blocks[1], 1))))
end
# Define Matrix multiplication between an array and an encrypted array
function (*::Encrypted{typeof(*)})(a::Array{T, 2}, b::Encrypted{Array{T, 2}}) where {T}
result = repeat(diag(a), inner=size(a, 1)).*x
rotated = b
for k = 2:size(a, 2)
rotated = ToyFHE.rotate(GaloisKey(*), rotated)
result += repeat(diag(circshift(a, (0,(k-1)))), inner=size(a, 1)) .* rotated
end
result
endThe end result of all of this that the user should be able to write the whole thing above with minimal manual work:
kp = keygen(ckks_params)
ek = keygen(EvalMultKey, kp.priv)
gk = keygen(GaloisKey, kp.priv; steps=64)
# Create evaluation context
ctx = Encrypted(ek, gk)
# Do public preprocessing
batch = ExplodedConvArray{eltype(batch)}(cdims, batch);
# Run on encrypted data under the encryption context
Cresult = ctx(model)(encrypt(kp.pub, batch))
# Decrypt the answer
decrypt(kp, Cresult)Of course, even that may not be optimal. The parameters of the cryptosystem (e.g. the ring ℛ, when to modswitch, keyswitch, etc) represent a tradeoff between precision of the answer, security and performance and depend strongly on the code being run. In general, one would want the compiler to analyze the code it's about to run encrypted, suggest parameters for a given security level and desired precision and then generate the code with minimal manual work by the user.
Conclusion
Achieving the dream of automatically executing arbitrary computations securely is a tall order for any system, but Julia's metaprogramming capabilities and friendly syntax make it well suited as a development platform. Some attempts at this have already been made by the RAMPARTS collaboration (paper, JuliaCon talk), which compiles simple Julia code to the PALISADE FHE library. Julia Computing is collaborating with the experts behind RAMPARTS on Verona, the recently announced next generation version of that system. Only in the past year or so has the performance of homomorphic encryption systems reached the point where it is possible to actually evaluate interesting computations at speed approaching practical usability. The floodgates are open. With new advances in algorithms, software and hardware, homomorphic encryption is sure to become a mainstream technology to protect the privacy of millions of users.
If you would like to understand more deeply how everything works, I have tried to make sure that the ToyFHE repository is readable. There is also some documentation that I'm hoping gives a somewhat approachable introduction to the cryptography involved. Of course much work remains to be done. If you are interested in this kind of work or have interesting applications, do not hesitate to get in touch.
About the Author

JuliaHub
Discover key content authored by JuliaHub experts. Stay updated on innovative practices in scientific and technical computing.
.jpg)
